1. 머신러닝
training
 |
forward되는 모델
하지만 이것은 정제된 데이터만을 학습할 수 있다.
딥러닝은 이러한 과정을 데이터에 상관없이 할 수 있다.(cnn)
forward는 wx+b
아래는 마지막 단계인 activation 단계이다.
1) linear regression


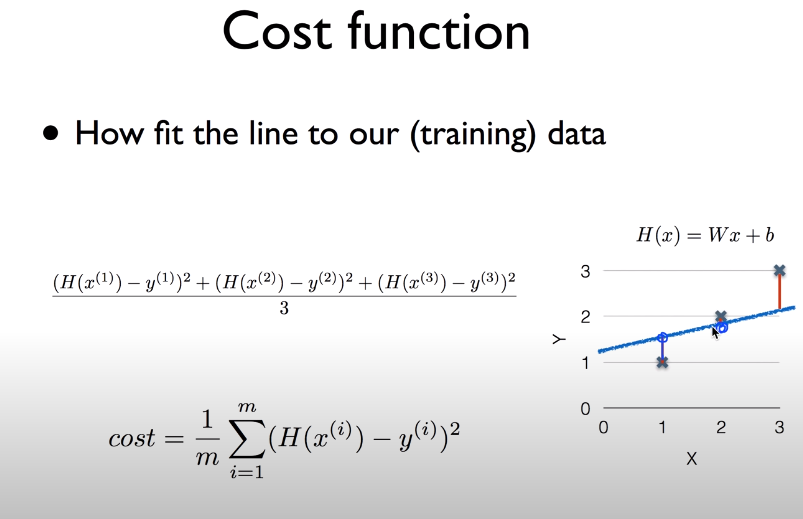
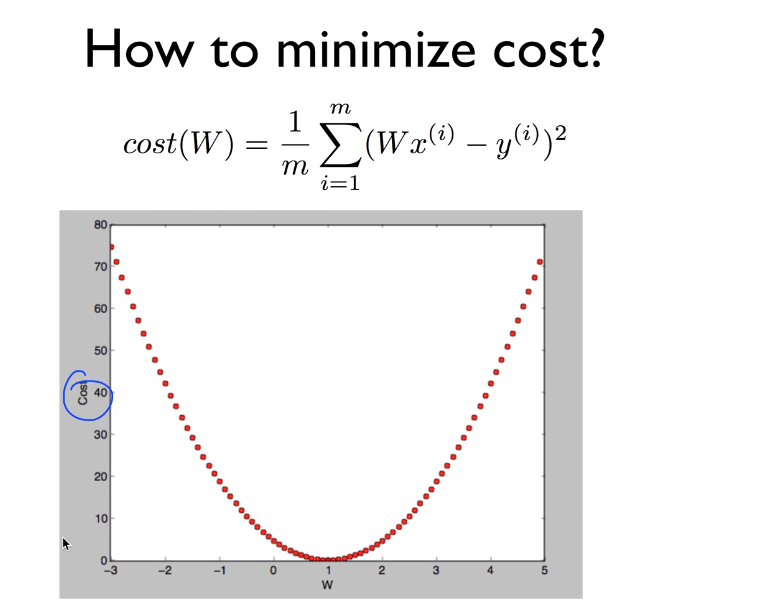


2) logistic classification(regression)
결과값이 0과 1일 경우
linear regression이 맞지 않는다.


예측(linear regression, logistic classification 사용)을 했으면 cost를 구하고 이를 minimize해줘야 한다.
training 과정
| forward(wx+b) ->activation(regression, classification) -> compute loss(cost) -> minimize cost(gradient descent algorithm) -> W update |
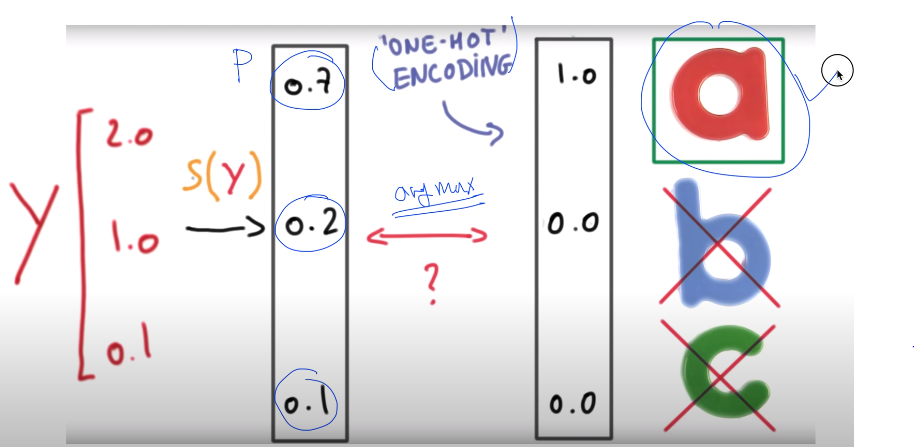
3) Softmax classification

multinomial classification 중 대표 유형
linear regression 이미지 참고 사이트
신경망
translated by Haesun Park English 中文 español français 日本語 신경망(neural network)이 처음 고안된 것은 거의 100여년 전으로 에이다 러브레이스는 “신경 시스템에 대한 수학
ml4a.github.io
- supervised learning - training set : regression, classification
ML 개요
기계 학습(Machine Learning, 머신 러닝)은 즐겁다! Part 1
(원문 : Machine Learning is Fun! by Adam Geitgey)
medium.com
현재의 기계 학습 알고리즘은 그런 수준은 아닙니다 — 매우 구체적이고 제한적인 문제에 초점을 맞춘 경우에만 동작합니다. 이러한 경우 “학습”에 대한 더 나은 정의는 “약간의 샘플 데이터를 기반으로 특정 문제를 해결하기위한 방정식을 알아내는 것”이 될 수 있습니다.
불행하게도”약간의 샘플 데이터를 기반으로 특정 문제를 해결하기위한 방정식을 알아내는 기계”는 그렇게 좋은 이름은 아닙니다. 그래서 우리는 대신 “기계 학습”이라고 부릅니다.
각 재료가 최종 가격에 얼마나 많은 영향을 미치는지 파악할 수 있다면, 이 최종 가격을 만들어줄 혼합 재료의 정확한 비율이 있을 것입니다.
만약 모든 주택에 적용할 수 있는 완벽한 가중치를 찾아낼 수만 있다면, 우리의 함수는 집값을 예측할 수 있을 것입니다!
Step 1:
먼저 가중치를 1.0로 하고 시작합니다:
Step 2:
그리고 알고있는 모든 주택 데이터를 당신의 함수를 통해 실행해보고 각 주택의 정확한 가격과 이 함수가 얼마나 차이가 나는지 살펴보는 것입니다:

당신의 함수를 이용해서 각 주택의 가격을 예상해 보세요.
예를 들어, 첫번째 주택은 실제로는 $250,000에 판매되었고, 당신의 함수는 $178,000에 판매되었다고 추정한것인데, 이 주택 하나만 보더라도 $72,000만큼 차이가 납니다.
이제 데이터 세트에 있는 각 주택 마다 차이난 가격의 제곱값을 추가해 보겠습니다. 데이터 세트에는 500 개의 주택 판매 정보가 있었고 각 주택에 대해 당신의 함수가 추정한 값과 실제 가격의 차이를 제곱한 값의 총합은 $86,123,373라고 가정해 보겠습니다. 이를 통해 당신이 함수가 현재 얼마나 “잘못되었는지” 알 수 있습니다.
이제, 이 합계를 500으로 나눠서 각 주택별로 얼마나 차이가 나는지 평균값을 구해보겠습니다. 이 평균 오류 값을 이 함수의 비용(cost)이라고 하겠습니다.
당신이 가중치를 잘 조정해서 이 비용을 0으로 만들 수 있다면, 당신의 함수는 완벽해지게 됩니다. 다시 말해서, 모든 경우에 대해서 당신의 함수가 입력 데이터를 기반으로 주택 가격을 완벽하게 추정할수 있다는 것을 의미합니다. 네, 다른 가중치를 시도해서 가능한 이 비용을 낮추려는 것, 이것이 바로 우리의 목표입니다.
Step 3:
가능한 모든 가중치를 조합해서 2 단계를 계속 반복합니다. 어떤 조합의 가중치든 비용을 0에 가깝게 만들어 주는 것을 사용하면 됩니다. 이런 가중치를 찾으면 문제를 해결한 것입니다!
앞서 설명한 3 단계의 알고리즘을 다변수 선형 회귀(multivariate linear regression)라고 부릅니다. 사실 당신은 모든 주택 데이터 값에 대해 딱 맞는 직선 방정식을 계산하는 것입니다. 그리고 이 방정식을 사용해서 이전에 보지 못했던 주택의 판매 가격을 추정할 수 있는 것입니다. 이는 정말이지 강력한 아이디어이며, 당신은 이 방법으로 “진짜” 문제를 해결할 수 있습니다.
그러나 지금까지 설명한 접근 방식이 단순한 경우에는 효과가 있지만, 모든 경우에 동작하지는 않습니다. 한 가지 이유는 집값이 항상 연속적인 직선을 따라갈만큼 단순하지 않기 때문입니다.
다행히도 이를 처리 할 수 있는 많은 방법들이 있습니다. 비선형 데이터 (예를 들어, 신경망(neural networks) 또는 SVMs 과 kernels)를 처리 할 수있는 많은 기계 학습 알고리즘이 있습니다. 선형 회귀(linear regression)를 보다 영리하게 사용해서 더욱 복잡한 선을 맞추는 방법도 있습니다. 이런한 모든 방법에는 최상의 가중치를 찾아야한다는 동일한 기본 아이디어는 여전히 적용되고 있습니다.
Step 3에서 “모든 숫자를 시도해보는 것”은 무슨 뜻인가요?
물론, 실제로 모든 가중치의 모든 조합을 시도해서 가장 잘 작동하는 조합를 찾을 수는 없습니다. 당신이 시도 할 숫자 조합은 무한하기 때문에 당연하게도 영원히 걸릴 것입니다.
이것을 피하기 위해서, 수학자들은 많은 것을 시도하지 않고도 이러한 가중치에 대한 좋은 값을 빨리 찾을 수있는 영리한 방법을 알아냈습니다. 여기 그중 한가지 방법이 있습니다:
Gradient descent - Wikipedia
Optimization algorithm Gradient descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function. To find a local minimum of a function using gradient descent, we take steps proportional to the negative of
en.wikipedia.org
먼저, 위 Step 2를 나타내는 간단한 방정식을 작성합니다:
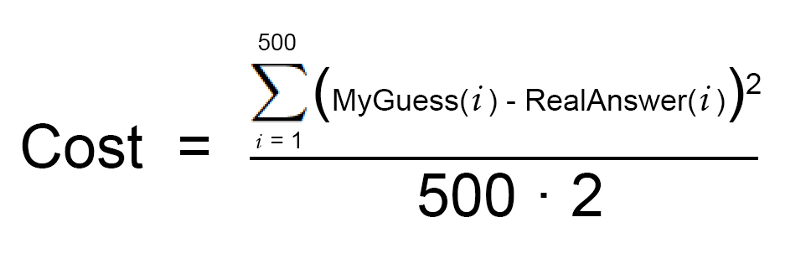
이 방정식이 바로 당신의 비용 함수(cost function) 입니다.
이제 완전히 똑같은 방정식을 재작성해 볼텐데, 대신 기계 학습의 수학 용어를 사용해 보겠습니다.(모르는 용어들은 지금은 그냥 무시하세요) :

θ는 현재 가중치를 나타냅니다. J(θ)는 ‘현재 가중치의 비용’ 을 의미합니다.
이 방정식은 현재 설정한 가중치에 대해 우리의 가격 추정 함수가 얼마나 차이 나는지를 나타냅니다.
이 그래프에서 파란색의 가장 낮은 지점이 비용이 가장 낮은 곳입니다 — 따라서, 우리의 함수는 조금 잘못되었습니다. 가장 높은 지점들이 가장 잘못된 것입니다. 즉, 우리가 이 그래프의 가장 낮은 지점으로 이동할 수 있는 가중치를 찾는다면, 우리는 답을 찾는 겁니다!

이제 그래프에서 가장 낮은 지점을 향해 “언덕을 걸어 내려 갈 수 있도록” 우리의 가중치를 조정해야 합니다. 만약 우리가 가장 낮은 지점으로 이동하도록 가중치를 조금씩 조정해 나간다면, 결과적으로 너무 많은 다른 가중치를 시도하지 않고도 그곳에 도달하게 될 것입니다.
따라서 각 가중치에 대한 비용 함수의 편미분을 계산하고, 각 가중치에서 해당 값을 뺄 수 있습니다. 이를 통해 우리는 언덕 맨 아래로 한 걸음 더 가까이 가게 됩니다. 이 작업을 계속하면 궁극적으로 언덕 맨 아래에 도달하여 가장 좋은 가중치를 얻게됩니다.
제일 이해 잘 되게 설명해놓은 자료
Neural Networks
Basic concepts for beginners
towardsdatascience.com
'AI > 이론' 카테고리의 다른 글
| [ML] Supervised/Unsupervised learning (0) | 2020.06.15 |
|---|---|
| [ML] Activation function (0) | 2020.06.15 |
| [ML] CNN(Convolutional Neural Network) (0) | 2020.06.12 |
| [ML] Backpropagation (0) | 2020.06.12 |
| [ML] AI, Machine Learning, Deep Learning (0) | 2020.06.12 |


