정의
- K개의 fold를 만들어서 진행하는 교차검증
사용 이유
- 총 데이터 갯수가 적은 데이터 셋에 대하여 정확도를 향상시킬수 있음
- 이는 기존에 Training / Validation / Test 세 개의 집단으로 분류하는 것보다, Training과 Test로만 분류할 때 학습 데이터 셋이 더 많기 때문
- 데이터 수가 적은데 검증과 테스트에 데이터를 더 뺐기면 underfitting 등 성능이 미달되는 모델이 학습됨

과정
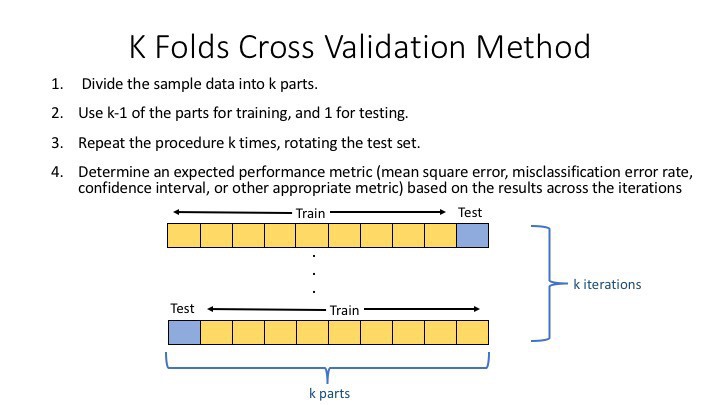
- 기존 과정과 같이 Training Set과 Test Set을 나눈다
- Training을 K개의 fold로 나눈다
- 위는 5개의 Fold로 나눴을때 모습이다
- 한 개의 Fold에 있는 데이터를 다시 K개로 쪼갠다음, K-1개는 Training Data, 마지막 한개는 Validation Data set으로 지정한다
- 모델을 생성하고 예측을 진행하여, 이에 대한 에러값을 추출한다
- 다음 Fold에서는 Validation셋을 바꿔서 지정하고, 이전 Fold에서 Validatoin 역할을 했던 Set은 다시 Training set으로 활용한다
- 이를 K번 반복한다
과정(이어서)
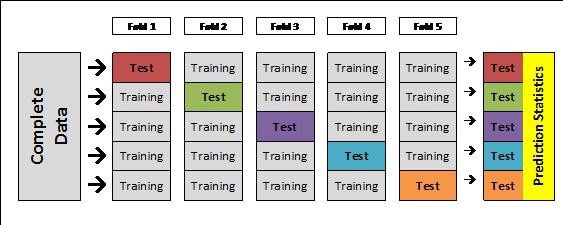
- 각각의 Fold의 시도에서 기록된 Error를 바탕(에러들의 평균)으로 최적의 모델(조건)을 찾는다
- 해당 모델(조건)을 바탕으로 전체 Training set의 학습을 진행한다
- 해당 모델을 처음에 분할하였던 Test set을 활용하여 평가한다
단점
- 그냥 Training set / Test set 을 통해 진행하는 일반적인 학습법에 비해 시간 소요가 크다
K-Fold Cross Validation(교차검증) 정의 및 설명
정의 - K개의 fold를 만들어서 진행하는 교차검증 사용 이유 - 총 데이터 갯수가 적은 데이터 셋에 대하여 정확도를 향상시킬수 있음 - 이는 기존에 Training / Validation / Test 세 개의 집단으로 분류하
nonmeyet.tistory.com
- 자세한 K-Fold 교차 검증 과정은 다음과 같다.
- 전체 데이터셋을 Training Set과 Test Set으로 나눈다.
- Training Set를 Traing Set + Validation Set으로 사용하기 위해 k개의 폴드로 나눈다.
- 첫 번째 폴드를 Validation Set으로 사용하고 나머지 폴드들을 Training Set으로 사용한다.
- 모델을 Training한 뒤, 첫 번째 Validation Set으로 평가한다.
- 차례대로 다음 폴드를 Validation Set으로 사용하며 3번 과정을 반복한다.
- 총 k 개의 성능 결과가 나오며, 이 k개의 평균을 해당 학습 모델의 성능이라고 한다.
예제 코드
- sklearn에서는 교차검증을 위해 cross_val_score 함수를 제공한다.

- KFold 상세 조정
- 위 cross_val_score 함수에서는, cv로 폴드의 수를 조정할 수 있었다.
- 만약 검증함수의 매개변수를 디테일하게 제어하고 싶다면
- 따로 검증함수 객체를 만들고 매개변수를 조정한 다음, 해당 객체를 cross_val_score의 cv 매개변수에 넣을 수도 있다.
- 이를 '교차 검증 분할기' 라고도 한다.

[ML] 교차검증 (CV, Cross Validation) 이란?
교차 검증이란? 보통은 train set 으로 모델을 훈련, test set으로 모델을 검증한다. 여기에는 한 가지 약점이 존재한다. 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결
wooono.tistory.com
'AI > 이론' 카테고리의 다른 글
| [ML] Transfer learning 2 (0) | 2021.12.30 |
|---|---|
| [ML] Fully Convolutional Layer, Fully Connected Layer, AutoEncoder (0) | 2021.12.28 |
| [ML] Ensemble - DL에 적용 (0) | 2021.11.09 |
| [ML] Curse of Dimension(차원의저주) (0) | 2021.11.05 |
| [ML] Activation2 - 존재하는 이유 (0) | 2021.11.05 |