Gradient descent : 에러를 미분하여 weight를 업데이트 하는 방법.
Back-propagation : Hidden node에서 에러를 미분하여 weight를 업데이트 하는 방법.
Feedforward

그럼 본격적으로 input을 네트워크에 입력하여 출력을 얻는 과정을 살펴보겠습니다.

input은 벡터로, weight는 행렬이므로 node의 출력은 행렬곱에 의해 구해집니다.

이렇게 구해진 node의 출력은 Activation 함수에 들어갑니다.

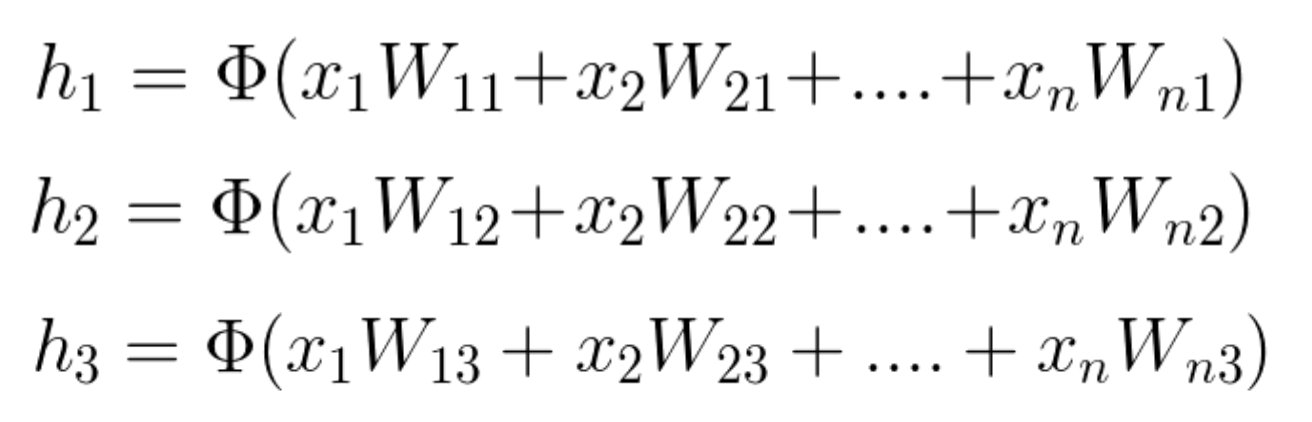
1-07. Multi Layer Perceptron 총정리
이제 1단원을 마무리하며 최종 정리 및 요약을 해보겠습니다. 이 포스트에 MLP(Multi Layer Perceptrons)의 내용을 모두 담았습니다. MLP를 훈련하기 위해서는 다음과 같은 과정을 거쳐야 합니다. Partial De
eungbean.github.io
Forward Propagation
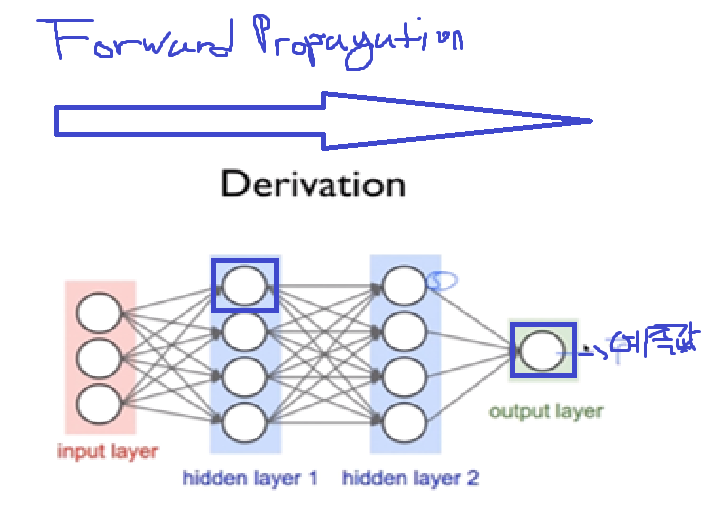
본격적으로 Back Propagation을 알아보기 전, 위 Neural Network에서 Layer 2의 첫번째 Unit을 최적화하며, Forward Propagation의 문제점을 알아보겠습니다.
우선 Cost를 구하기 위해서는 Neural Network의 예측값을 구해야합니다.
- 따라서 Output Layer에서의 최종적인 예측값을 구하기 위해서는, Layer 3의 4개의 Unit이 각각의 g(z)값을 Output Layer에 보내줘야 합니다.
- 근데 이 layer 3의 g(z)을 각각 구하기 위해서는, Layer 2의 unit들은 'Input Layer'에서 받은 Input으로 g(z)값 을 계산해서 Layer 3에 보내줘야합니다.
- 이렇게 구한 예측값을 실제값에서 빼면 Cost를 구할 수 있게 됩니다.

그러면 현재 우리는 Gradient Descent Algorithm을 이용하고 있으므로, 계산한 Cost의 미분값에 learning rate를 곱하여 가중치 W에서 뺌으로써 한번의 갱신이 이뤄집니다.
근데 여기서 끝이 아닙니다! 우리는 한번의 갱신을 한것이지 Cost를 최소화하기 위해 이 짓을 적게는 몇 백번, 많게는 몇 천번을 연산해줘야 합니다.
그러나 우리는 이 짓을 Neural Network에 있는 나머지 Unit들에 대해서 똑같이 다 해줘야 합니다.
만약 우리가 사용하려는 Neural Network의 Layer가 100개였다면 이러한 방식은 연산량이 무한대에 가까울 것이며 불가능합니다.
이처럼 Forward Propagation은 Neural Network가 커질수록 최적화를 위한 연산량이 기하급수적으로 늘어나게 됩니다.
한동안 전문가들은 이러한 문제에 봉착하여 한동안 연구가 진전되지 못하다가 나오게 된것이 바로 Back Propagation입니다.
Gradient descent algorithm 순서
- 현재 weight에서 모든 데이터에 대해 loss를 구해서 미분한다.
- 미분한 값이 gradient(=기울기)가 된다.
- 기울기가 양수면 음수방향으로 a(learning rate)만큼 이동한다. (weight를 수정한다.)
- minima에 도달할 때 까지 반복한다.
머신러닝 알고리즘 - Linear Regression (선형 회귀), Hypothesis, Cost Function, Gradient Descent
파이썬 텐서플로우(TensorFlow) 스터디 관련 글 더보기 텐서플로우 예제 깃허브(GitHub) 페이지머신러...
blog.naver.com
구현코드
경사하강법 (Gradient Descent) 직접 구현하기
경사하강법 (Stocastic Gradient Descent) 직접 구현하는 방법에 대해 알아보겠습니다.
teddylee777.github.io
'AI > 이론' 카테고리의 다른 글
| [ML] End-to-End Deep Learning (0) | 2021.06.25 |
|---|---|
| [ML] Sigmoid, ReLu (0) | 2021.06.03 |
| [ML] Softmax regression, Categorical Cross-Entropy Loss, Multi-class Classification (0) | 2021.06.02 |
| [ML] Epoch, iteration, batch size (0) | 2021.06.01 |
| [ML] Transfer learning1 (0) | 2021.05.22 |
